Die Zukunft der Unternehmensinformationen: Wissensdatenbank-Suche
Eine Open Source Dokument des Volkswagen-Konzerns wurde als Beispiel für die Funktionsweise der Retrieval Augmented Generation (RAG) Knowledge Base Search herangezogen. Dieses Dokument kann öffentlich eingesehen und heruntergeladen werden. Hinweis: Wir sind nicht mit dieser Organisation verbunden (es ist nur ein Beispiel-PDF, das wir online finden konnten…)

Versuchen Sie, eine Frage für die Suchleiste der Wissensdatenbank zu stellen
Wie es funktioniert
01/
Die RAG speichert Ihre Unternehmensdokumente sicher in einem Vektorspeicher
02/
Die Benutzer schreiben die Frage von Interesse aus diesem Dokument.
03/
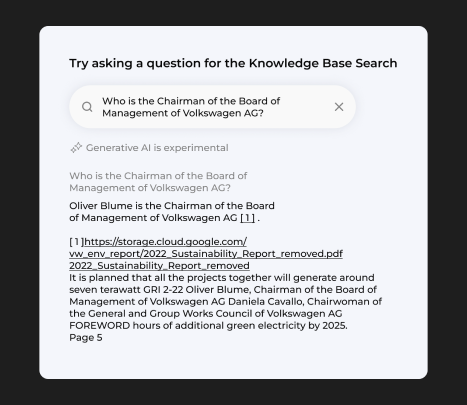
Die Suchleiste gibt eine klare Antwort und kann zeigen, auf welcher Seite detaillierte Informationen zu der gestellten Frage zu finden sind, ohne dass Halluzinationen entstehen.
Visualisierung unseres Ansatzes
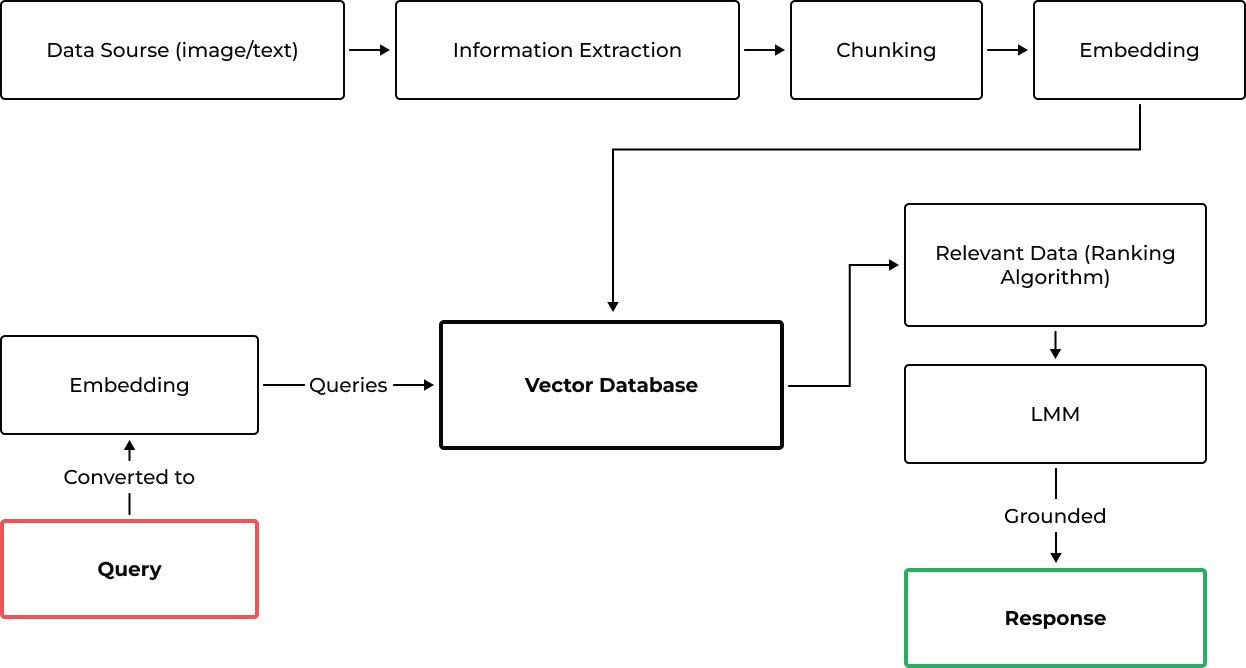
Das Herzstück unserer innovativen Plattform ist das Retrieval Augmented Generation (RAG) System. Stellen Sie sich einen digitalen Bibliothekar vor, der nicht nur Bücher verstehen und durchsuchen kann, sondern auch ein Universum digitaler Inhalte, einschließlich Bildern und Texten. Genau das tut unser RAG-System – es wählt sorgfältig die wichtigsten Informationen aus einer riesigen Datenmenge aus. So wie ein Koch die Zutaten für ein Gourmet-Gericht zerkleinert, zerlegt unser System die Informationen in mundgerechte Stücke. Diese Stücke oder „Chunks“ werden dann in einen speziellen Code umgewandelt, der als Einbettung bezeichnet wird und den unser System schnell verstehen und analysieren kann. Stellen Sie sich diese Einbettungen wie Einträge in einem superschnellen digitalen Bibliothekskatalog vor, die alle an einem Ort gespeichert sind, den wir Vektordatenbank nennen. Wenn Sie eine Frage stellen, wandelt unser System Ihre Worte in einen ähnlichen Code um und findet schnell die beste Übereinstimmung in diesem Katalog. Das ist wie die Suche nach dem perfekten Buch in einer Bibliothek, nur eben blitzschnell.
Das Wunder geschieht, wenn unser Sprachlernmodell (LLM) ins Spiel kommt. Es ist wie ein weiser Weiser, der die Informationen aufnimmt und eine Antwort erstellt, die nicht nur korrekt ist, sondern auch auf den Kontext Ihrer Frage zugeschnitten ist. So wird sichergestellt, dass Sie Antworten erhalten, die Sinn machen und echte Erkenntnisse liefern. Indem wir die sorgfältige Vorbereitung der Datenerfassung und -organisation mit der kreativen Note unseres LLM kombinieren, erhalten Sie Antworten, die mehr als nur Datenpunkte sind – sie sind aussagekräftig, relevant und mit Sorgfalt ausgearbeitet. Es ist diese Kombination aus Datenpräzision und menschenähnlichem Verständnis, die Ihr Kundenerlebnis auf die nächste Stufe hebt und dafür sorgt, dass sich jede Interaktion mit unserem Service intuitiv, hilfreich und beeindruckend intelligent anfühlt.
Ein Beispiel für die Suche und Konversation mit Vertex AI
Datenextraktion und Einbettung
Die Daten werden zunächst extrahiert, in kleine Textabschnitte (Chunks) unterteilt und dann werden Einbettungen (d. h. diesen Textabschnitten werden numerische Werte zugewiesen, die auch Vektoren genannt werden) erstellt.

Antworten auf Abfragen
Die Abfrage gibt Antworten zurück, indem sie einen Relativitätsalgorithmus verwendet, um die Einbettungen zu finden, die näher an den Einbettungen der Frage liegen, und mit einer passenden Antwort zu antworten.
Antworten auf Bildabfragen
Wenn Sie eine Abfrage auf der Grundlage eines Bildes stellen möchten, z. B. ein Bild einer Tabelle, geben Sie einfach das Bild ein, und die Vektordatenbank findet das entsprechende Bild in den Dokumenten und gibt es Ihnen zurück. Hier werden wir „Multimodales Lernen“ verwenden.
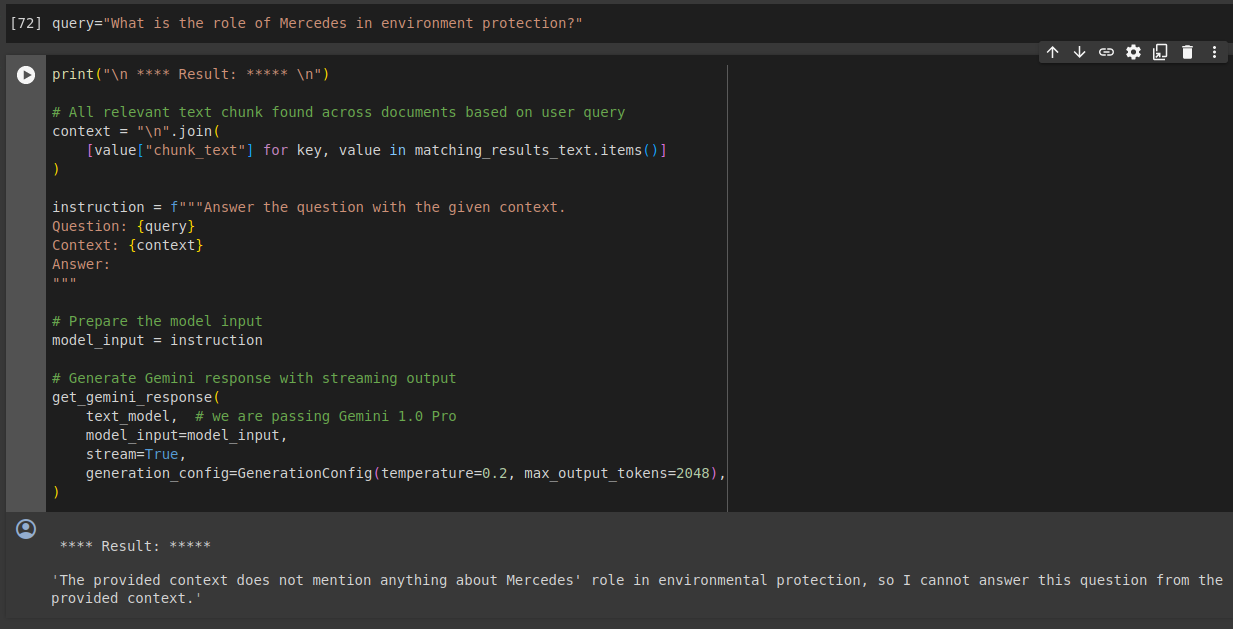
Fundierte Antworten
RAG ermöglicht es uns, die Antworten des Benutzers auf tatsächlich übereinstimmenden Text zu gründen, ohne dass es zu Halluzinationen kommt. Wenn die relevanten Informationen nicht vorhanden sind, liefert die App keine zufälligen Informationen, sondern antwortet mit einer entschuldigenden Nachricht, dass die erforderlichen Informationen nicht vorhanden sind. Wie in der Referenz-PDF-Datei zu sehen ist, wird Mercedes in dem Dokument nicht erwähnt. Dies ist besonders nützlich, wenn unternehmensbezogene Informationen erforderlich sind.