Pipelining beim maschinellen Lernen: Effiziente Erschließung KI für Unternehmen
ML Pipelining verstehen
- Pipelining für maschinelles Lernen (ML) ist eine wichtige Technologie, die Unternehmen dabei hilft, KI-Workflows zu optimieren.
- Sie ermöglicht eine effiziente Entwicklung und Bereitstellung von ML-Modellen und macht Prozesse skalierbar.
Bedeutung des ML Pipelining
- ML Pipelining automatisiert den gesamten Prozess der Entwicklung und Bereitstellung von Machine-Learning-Modellen.
- Diese Automatisierung umfasst verschiedene Phasen: Datenerfassung, Datenvorverarbeitung, Modellschulung, Modellbewertung, Modellbereitstellung.
ML Pipelining für Unternehmen
- ML Pipelining vereinfacht und automatisiert die komplexen Aufgaben, die mit der Entwicklung und Bereitstellung von ML-Modellen verbunden sind, und verbessert so letztlich die Effizienz und Skalierbarkeit.
Erleben Sie die Zukunft mit uns
Indem sie alle Schritte in einer kohärenten Pipeline organisieren, können Unternehmen sicherstellen, dass ihre ML-Workflows reproduzierbar, skalierbar und einfacher zu verwalten sind.
Die Vorteile von ML Pipelining
Effizienz und Geschwindigkeit
Durch die Automatisierung sich wiederholender Aufgaben innerhalb des ML-Workflows wird die für die Entwicklung und den Einsatz von Modellen erforderliche Zeit erheblich verkürzt. Dadurch können Unternehmen schneller auf Marktveränderungen und Kundenbedürfnisse reagieren.
Skalierbarkeit
Pipelining erleichtert die Verarbeitung großer Datenmengen und komplexer Modellierungsprozesse und ermöglicht es Unternehmen, ihre KI-Lösungen zu skalieren, wenn sie wachsen, ohne Kompromisse bei der Leistung einzugehen.
Konsistenz und Qualität
Durch die Standardisierung des ML-Workflows stellt das Pipelining sicher, dass jeder Schritt des Prozesses den Qualitätsstandards des Unternehmens entspricht, was zu zuverlässigeren und genaueren Modellen führt.
Kostenreduzierung
Durch Automatisierung und Effizienz kann ML-Pipelining die mit der manuellen Datenverarbeitung und der iterativen Modellabstimmung verbundenen Kosten erheblich senken.
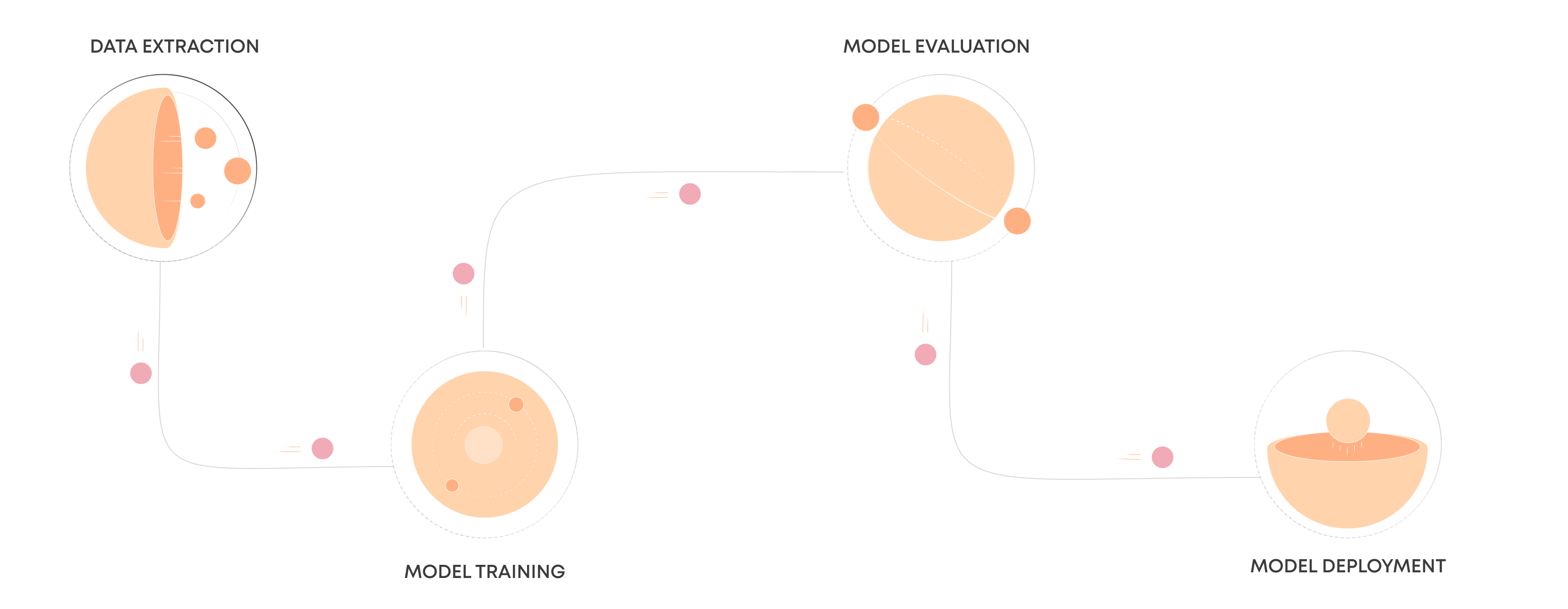
ML Pipeline
01/
Datenerfassung und Vorverarbeitung
Die Reise beginnt mit der Datenerfassung und -vorverarbeitung, einem grundlegenden Schritt, bei dem Rohdaten aus verschiedenen Quellen wie Datenbanken, Online-Repositories oder Sensoren gesammelt werden. Diese Rohdaten enthalten oft Ungenauigkeiten, fehlende Werte oder irrelevante Informationen, die einer gründlichen Bereinigung und Normalisierung bedürfen, damit sie in ein brauchbares Format gebracht werden können. Durch die Vorverarbeitung werden diese Rohdaten in eine strukturierte Form gebracht und für die Analyse geeignet gemacht, indem Probleme wie fehlende Daten, die Normalisierung von Datenskalen und die Kodierung kategorialer Variablen behoben werden, wodurch eine solide Grundlage für ein genaues Modelltraining geschaffen wird.
02/
Feature Engineering
Nach der Vorverarbeitung kommt das Feature-Engineering ins Spiel, das als Brücke zwischen Rohdaten und Vorhersagemodellen fungiert. Dieser Prozess umfasst die Extraktion, Auswahl und Umwandlung von Datenattributen (Features), um die Vorhersagekraft des Modells zu verbessern. Ein effektives Feature-Engineering kann die Erstellung neuer Features beinhalten, die zugrunde liegende Muster in den Daten erfassen, die Auswahl der relevantesten Features, um die Komplexität zu reduzieren, oder die Umwandlung von Features, um sie besser an die Modellannahmen anzupassen. Dieser Schritt ist für die Steigerung der Modellleistung von entscheidender Bedeutung, da die richtigen Merkmale die Lernfähigkeit eines Modells aus den Daten erheblich verbessern können.
03/
Modell Training
Mit den vorbereiteten Daten und den besten Merkmalen gehen wir zum Modelltraining über, bei dem Algorithmen aus den Daten lernen. In dieser Phase werden die verarbeiteten Daten in verschiedene Algorithmen für maschinelles Lernen eingespeist, um Modelle zu erstellen, die Ergebnisse vorhersagen oder Daten in verschiedene Kategorien einordnen können. Die Wahl des Algorithmus hängt von der jeweiligen Aufgabe (z. B. Regression, Klassifizierung) und der Art der Daten ab. Während des Trainings passt das Modell iterativ seine Parameter an, um die Fehler bei den Vorhersagen zu minimieren und die Muster im Trainingsdatensatz effektiv zu lernen.
04/
Bewertung & Validierung
Sobald ein Modell trainiert ist, sind Bewertung und Validierung entscheidend für die Beurteilung seiner Leistung. Dabei werden Metriken wie Genauigkeit, Präzision, Rückruf oder mittlerer quadratischer Fehler verwendet, um zu messen, wie gut das Modell Vorhersagen für Daten trifft, die es noch nicht gesehen hat. Validierungstechniken wie die Kreuzvalidierung tragen dazu bei, sicherzustellen, dass die Leistung des Modells über verschiedene Datenuntergruppen hinweg konsistent ist, um eine Überanpassung zu verhindern, bei der ein Modell die Trainingsdaten zu gut lernt, aber bei neuen Daten schlecht abschneidet. Dieser Schritt bestätigt, ob das Modell für den Einsatz in der realen Welt bereit ist oder ob weitere Anpassungen erforderlich sind.
05/
Inbetriebnahme
Erfolgreiche Modelle gehen dann in die Einsatzphase über, in der sie in operative Systeme integriert werden, um erste Erkenntnisse oder Vorhersagen in einer realen Umgebung zu liefern. Der Einsatz kann sehr unterschiedlich sein, von der Einbettung der Modelle in bestehende Softwareanwendungen bis hin zum Einsatz auf Cloud-basierten Plattformen für die Skalierbarkeit. In dieser Phase interagiert das Modell mit neuen Daten in Echtzeit- oder Batch-Prozessen und liefert wertvolle Erkenntnisse oder automatisierte Entscheidungen zur Verbesserung von Geschäftsprozessen oder Benutzererfahrungen.
06/
Überwachung und Wartung
Schließlich gewährleisten Überwachung und Wartung die Langlebigkeit und Relevanz der eingesetzten Modelle. Im Laufe der Zeit können die Modelle aufgrund von Änderungen der zugrunde liegenden Datenmuster oder externer Bedingungen von ihrer ursprünglichen Leistung abweichen. Eine regelmäßige Überwachung ermöglicht die Erkennung solcher Veränderungen und veranlasst bei Bedarf eine Umschulung oder Anpassung des Modells. Zur Wartung gehört auch die Aktualisierung der Datenvorverarbeitungsschritte oder -funktionen, um die Genauigkeit und Relevanz des Modells aufrechtzuerhalten und sicherzustellen, dass es seine Ziele in einem sich verändernden Umfeld weiterhin erfüllt.
Nutzung von ML Pipelining als Wettbewerbsvorteil
Durch den Einsatz von ML Pipelining können Unternehmen nicht nur ihre KI-Workflows optimieren, sondern auch Innovation und Agilität innerhalb ihrer Abläufe fördern. Mit dieser Technologie können Unternehmen ausgefeilte ML-Modelle einsetzen, die das Kundenverhalten vorhersagen, betriebliche Prozesse optimieren und verwertbare Erkenntnisse liefern können, um so Wachstum und Effizienz zu steigern.
Zusammenfassend lässt sich sagen, dass ML Pipelining einen transformativen Ansatz für Unternehmen darstellt, die die Leistung von KI nutzen möchten. Durch die Automatisierung und Optimierung des ML-Workflows können Unternehmen schnellere Entwicklungszyklen erreichen, die Modellgenauigkeit verbessern und die Betriebskosten senken – alles wichtige Faktoren, um auf dem heutigen schnelllebigen Markt einen Wettbewerbsvorteil zu erzielen.