Große Sprachmodelle (LLMs), die auf GPUs laufen, verbrauchen viel Energie und belasten die Umwelt. Das Ziel des Fortschritts in der künstlichen Intelligenz (KI) ist es, dem menschlichen Leben im Alltag zu helfen und gleichzeitig die Umwelt zu schützen. Um diese Bedenken anzugehen, hat Microsoft Research BitNet eingeführt, eine 1-Bit-Transformer-Architektur, die speziell für großskalige Sprachmodelle entwickelt wurde. Dieser neuartige Ansatz zielt darauf ab, die Ressourcenanforderungen für das Training und die Bereitstellung dieser Modelle zu reduzieren, während eine wettbewerbsfähige Leistung im Vergleich zu modernsten 8-Bit-Quantisierungsmethoden und FP16-Transformer-Baselines beibehalten wird.
BitNet funktioniert, indem es eine 1-Bit-Transformer-Architektur einführt, die für große Sprachmodelle optimiert ist. Die Kerninnovation ist die BitLinear-Schicht, die die traditionelle Gleitkomma-Matrixmultiplikation durch 1-Bit-Gewichte ersetzt, wodurch der Speicherbedarf und die Rechenanforderungen des Modells drastisch reduziert werden. BitNet quantisiert Modellgewichte zu binären Werten (+1 oder -1) unter Verwendung der Signum-Funktion und wendet die absmax-Quantisierung für Aktivierungen an, um sicherzustellen, dass das Modell effizient mit arithmetischen Operationen niedriger Präzision arbeitet. Während des Trainings nutzt BitNet Techniken wie LayerNorm und Straight-Through Estimators (STE), um den Gradientenfluss und die Trainingsstabilität trotz der reduzierten Präzision aufrechtzuerhalten. Darüber hinaus integriert es Gruppenquantisierung und normalisierung, um eine effiziente Modellparallelität zu ermöglichen, was eine skalierbare Leistung bei großen Modellen bei gleichzeitiger Minimierung des Kommunikationsaufwands zwischen den Geräten gewährleistet. Diese Architektur führt zu erheblichen Einsparungen beim Energieverbrauch und Speicherbedarf, während die Leistung auf dem Niveau von Modellen mit voller Präzision bleibt.
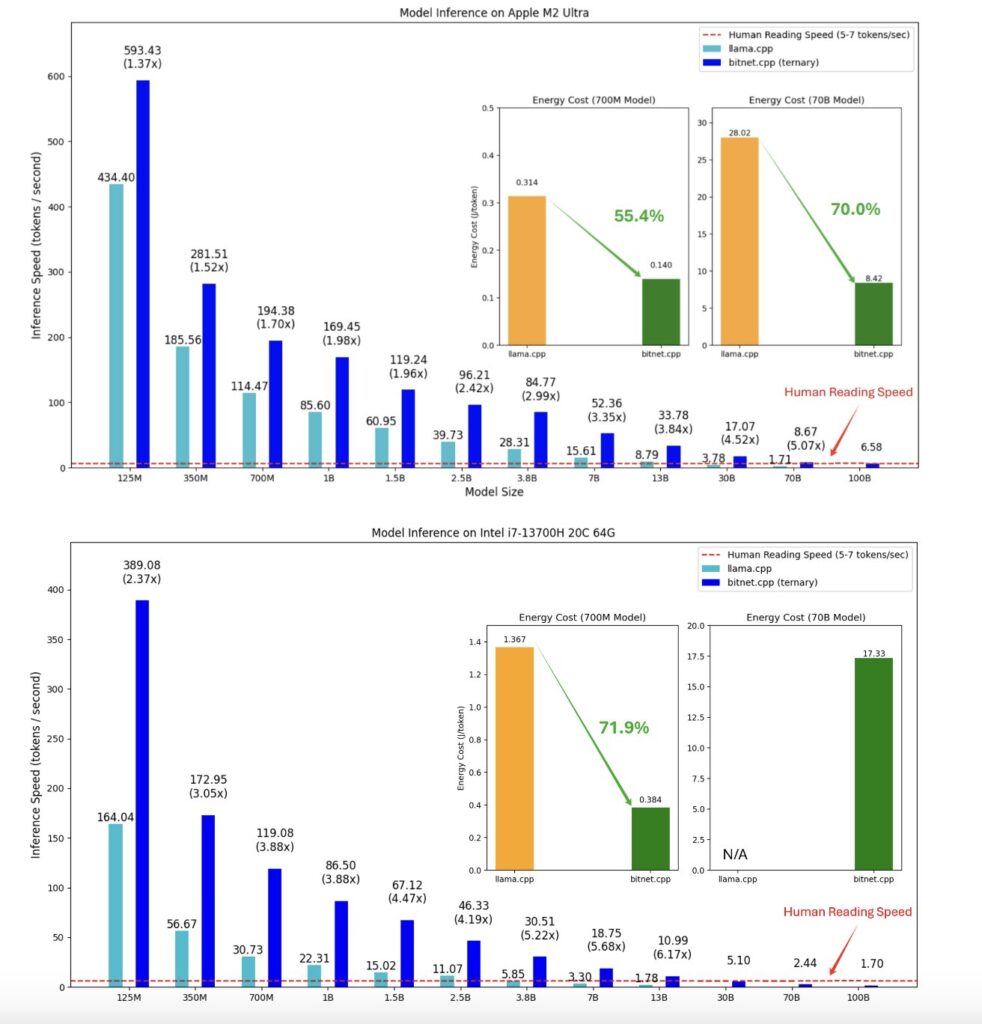
BitNet stellt einen bedeutenden Fortschritt bei der Optimierung großer Sprachmodelle durch 1-Bit-Quantisierung dar, da es den Speicherbedarf, den Energieverbrauch und die Rechenkosten im Vergleich zu FP16-Transformern reduziert. Seine innovativen Funktionen, wie BitLinear und absmax-Quantisierung, bewahren die Leistung und verbessern gleichzeitig die Effizienz, was eine skalierbare Bereitstellung auf herkömmlicher Hardware ermöglicht. Da BitNet nun Open Source ist, bietet es eine vielversprechende Lösung für reale KI-Anwendungen, die hohe Leistung mit reduzierten Ressourcenanforderungen in Einklang bringt. Open-Source-Projekte wie diese werden die Entwicklung der KI in eine positive Richtung lenken. Dies kommt der Gemeinschaft zugute und schafft eine harmonische Kultur, in der jeder zur Entwicklung der Zukunft seiner Träume beitragen kann.
References
Hongyu Wang et al. “BitNet: Scaling 1-bit Transformers for Large Language Models” Microsoft 2024